
How a 22 year old from Shanghai won a global deep learning challenge


In our 2nd public research challenge contestants were faced with using deep learning to solve for a vehicle detection algorithm that can adapt to change. Researchers worldwide got to test their skills, win prizes (1st place $5,000, 2nd place $2,000, 3rd place $1,000), and join our mission to make the roads safer. We were impressed by the grit and enthusiasm of our challengers, and by the amazing results they achieved.
Nexar builds the world’s largest open vehicle-to-vehicle (V2V) network by turning smartphones into connected AI dashcams. Joining deep learning with millions of crowdsourced driving miles collected by our users, Nexar’s technology provides a new, safer driving experience with the potential of saving the lives of 1.3 million people who die on the world’s roads every year.
Today we are excited to officially announce the winners of the second Nexar Challenge (Vehicle Detection in the Wild using the NEXET Dataset) and tell their stories.
The Challenge
At Nexar, we are building an Advanced Driver Assistance System (ADAS) based on a monocular camera stream from regular consumer dashcams mounted on cars all across the planet. These cameras are continuously taking images of the world’s roads in all weather, light conditions, and driving scenarios.
In this challenge, we asked contestants to build a rear vehicle detector function that computes bounding boxes around each clearly visible vehicle in front. The detector should be looking for vehicle(s) in front of the camera that are driving in the same direction as the driver. The purpose of this perception task is to improve Nexar’s Forward Vehicle Collision Warning feature, which requires a very accurate bounding box around the rear of the vehicle(s) ahead.
The NEXET dataset
For this challenge, we released one of the largest and most diverse road datasets in the world. Our vision of a collision free world is a global group effort, and so we decided to release part of our training data for other researchers to benefit from the vast imagery and videos Nexar collects on a daily basis.
The dataset was released for our contestants and soon it will be available as a free dataset for researchers worldwide. See this blog post for more information about this dataset: NEXET — The Largest and Most Diverse Road Dataset in the World
Results
We opened this challenge to researchers from around the world, and were happy to see that the deep learning AI revolution extends to the farthest areas of the globe. We saw researchers from Russia, India, USA and Israel, a couple from Bolivia, Bangladesh, Malaysia, Morocco and 40 other different countries, and the winners coming from China, Australia and South Korea.
It was a tight competition with over 400 challenge registrants and 29 submissions; we saw networks varying from a SSD based on VGG weighing 97 MB, through a 771MB ensemble of networks, and onto the winner’s Deformable R-FCN based on Resnet weighing only 130MB.
Here are some interesting statistics about the challenge results:

- We saw several frameworks being used. TensorFlow was our contestants favorite and was used by more than half of them
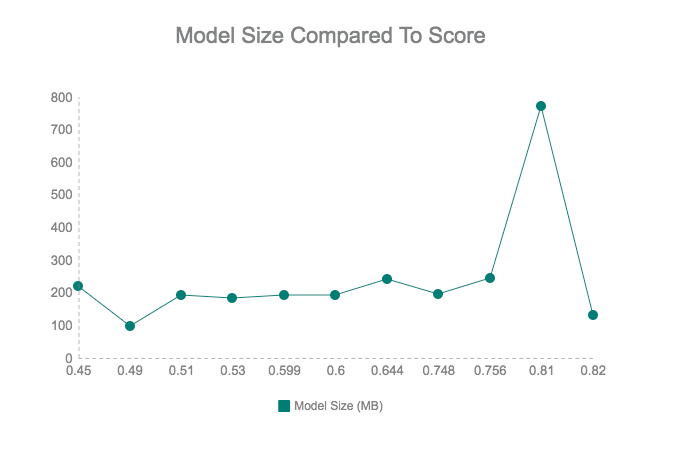
- We got a variety of networks — including ensembles of multiple networks, which resulted in very big models, but in the end we saw that size, usually, doesn’t matter
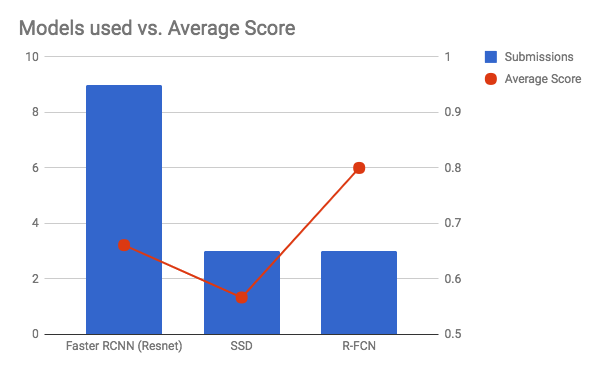
- Most of our contestants used Faster RCNN for their model, which gave a variety of scores ranging from 0.5 to 0.77. But our clear winner was Deformable R-FCN with an average score of 0.8
The contest was fierce. Our contestants kept stretching the boundaries of their networks, improving them over and over. Finally, with less than an hour until the submission closed, a 22-year-old senior undergraduate from Fudan University, Shanghai, China managed to achieve the highest score, beating all the great minds that took part in the challenge.
We will let the leading participants take it from here.
1st Place ($5,000): Hengduo Li (Henry)

“Currently a senior undergraduate in Fudan University, Shanghai, China. I’m interested in computer vision and have spent some days on topics like human detection, object detection, etc. I hope to continue working on these topics in my future study which help us in our real life, like what Nexar is doing :)”
“I used Deformable R-FCN with soft-NMS for the challenge. A single model is trained from ResNet-50 pre-trained on ImageNet.”
Takeaways:
1. Deformable Convnets and R-FCN is powerful and gets state-of-the-art performance on ImageNet and COCO. I didn’t need to use ensemble. If ensemble and ResNet-101 are used together with some more tricks, performance can be better.
2. Horizontally flipping the training images works well. I flipped all the training data horizontally and used them. This is already a generally taken data augmentation method.
3. Small size anchors. Viewing the training data, I saw many small boxes and decided to add more small size anchors. It worked well.
4. Multi-scale testing. This generally adds about 2% performance improvement. I trained on 720, tested on (600, 720, 1000) and got the performance improvement.
2nd Place ($2,000): Dmytro Poplavskiy
Brisbane, Australia

Age: 38
Residence: Brisbane, Australia
Education: M.A. Radio Physics and Electronics
“I’m a software engineer with a recent interest in machine learning.
“Essentially the source code consists of
1) Deformable ConvNets modification of Faster-RCNN from https://github.com/msracver/Deformable-ConvNets
I made a few minor modifications, including the adapter to read Nexar dataset, option to disable non maximum suppression stage and a small script to run multiple predictions.
2) A few utility scripts to prepare dataset augmentations and convert results back.
3) Implementation of custom flexible non maximum suppression stage.”
Take Aways
- I decided to use Deformable ConvNets modification of Faster-RCNN or R-FCN.
- As it was allowed to modify/label the training dataset, I checked first how the training data could be improved.
- The size and nature of labels made manual re-labeling impractical.
- I split the training dataset to two folds and I trained R-FCN models on each fold.
- I compared the out of fold predictions with original labels and found all the boxes my model was confident about but missing in the training dataset.
- I found in almost all cases it indicated missing label.
- I sorted training images by number of missing boxes and re-labeled ~15–20% of images with most boxes missing, up to 8 cars in the worst case.
- Since the model produced quite accurate boxes I only had to choose which predicted boxes to add to the training dataset, so it was relatively quick process.
- I decided to use Faster-RCNN as it gives me slightly better result from a quick test comparing to R-FCN.
- I planned to try the Soft NMS approach described in https://arxiv.org/abs/1704.04503
- I extended the original idea of Soft NMS to adjust not only the confidence but boxes locations as well.
- I checked the results of Faster-RCNN before NMS stage and found it often produced a number of close boxes with similar confidence and position.
- To discard all the results except for the top confidence box sounds a bit wasteful. Even more when prediction from multiple models or test time augmentations combined.
So my Flexible NMS approach:
1) For a top confidence box, combine it with all other similar boxes with iou > 0.8, with box position as a weighted avg of box position with confidence⁴ weight.
2) For the confidence of combined box, I used conf = sum(conf of up to N top boxes)/N
This is especially useful for combining multiple results, I’d like to penalize results only one network found comparing to more confident results predicted by more networks/boxes of the single network.
I used N == 4*number of predictions combined.
3) For all the other boxes overlapped with the current box, I adjusted confidence as described in original soft nms article.
Overall this approach allowed me to increase score from ~0.72–0.73 with a single model and default NMS to 0.77–0.78 with ~6 predictions combined from 2 different models using flexible NMS.
For my final submission I trained 3 models of Faster RCNN, and for each predicted all images, flipped and +-20% resized.
I combined all the results with original NMS disabled and post processed with flexible NMS.
3rd Place ($1,000): Sang Jin Park
Seoul, South Korea

Age: 40
Residence: Seoul, S.Korea(ROK)
Education: Physics/CS B.S KAIST
Take Aways
- “To avoid overfitting, I used Dropout layers, as well as data augmentation such as horizontal flip, rotation and zoom.”
- “As for working tools, after trying to use Tensorflow straight up, I switched to Keras together Python notebooks, which helped experimentation and visualization a lot.”
- “Cropping — I had a feeling that cropping the lower half of the picture might help the training, but it seemed like this actually decreased the learning.”
- “I have spent many hours working with Amazon GPU instances which helped me experiment, but in the end, since the model size had to remain small, experimenting on my own laptop was fast.”
Special mention: Nick Sergievskiy managed to get a great result of 0.78 using a SSD based approach. Unfortunately it did not conform with our challenge terms. See his project here, https://github.com/dereyly/caffe
Congratulations once again to our winners! We wish to thank all of our challenge participants for taking part in our mission towards a collision free world. We hope that this challenge helped you in developing your skills and gave you a taste of what we do here at Nexar. Stay tuned for our next challenge!